| 2.14. Parallelism in Geant4: multi-threading capabilities | ||
|---|---|---|
 | Chapter 2. Design and Function of Geant4 Categories |  |
| 2.14. Parallelism in Geant4: multi-threading capabilities | ||
|---|---|---|
| | Chapter 2. Design and Function of Geant4 Categories | |
Geant4 event-level parallelism is based on a master-worker model in which a set of threads (the workers) are spawned and are responsible for the simulation of the events, while the steering and control of the simulation is given to an additional entity (the master).
Multithreading functionalities are implemented with new classes or modification to existing classes in the run category:
Additional information on Geant4 multi-threading model can be found in the next section.
In this chapter, after a brief reminder of basic design choices, we will concentrate on aspects that are important for kernel developers, in particular we will discuss the most critical aspect for multi-threading in Geant4: memory handling, split-classes and thread-local storage. In the following it is assumed that the user is already familiar with general aspects of multi-threading. The section Additional Material contains resources to additional information.
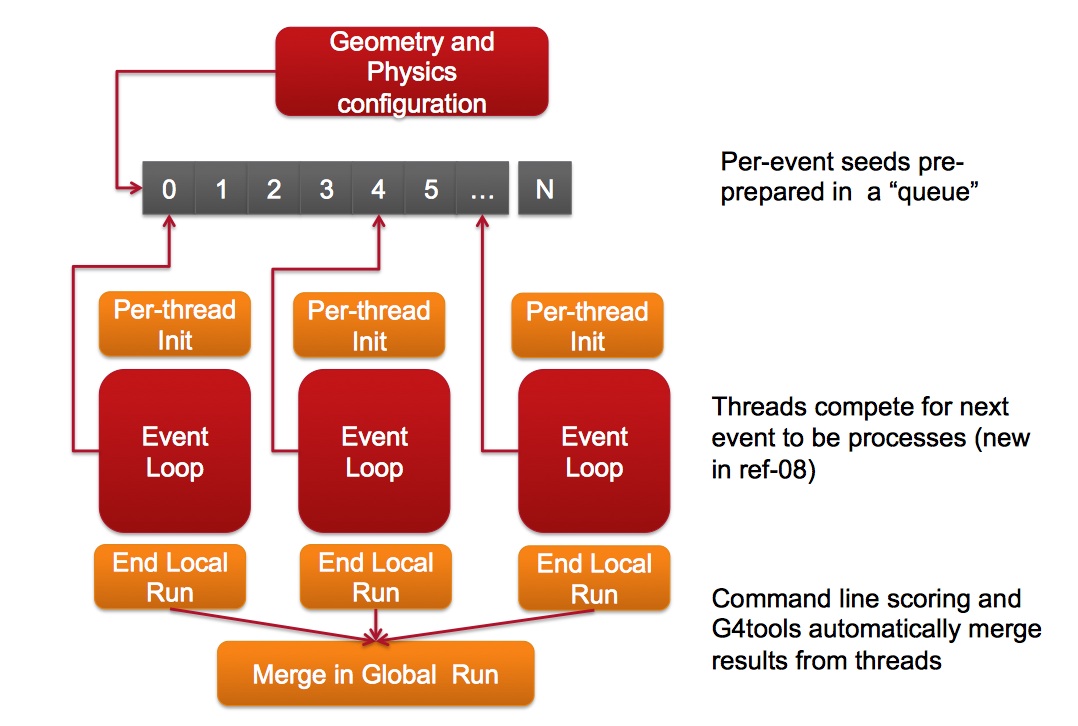
Geant4 Version 10.0 introduces parallelism at the event level: events are tracked concurrently by independent threads. The parallelism model is master-worker in which one or more threads are responsible of performing the simulation, while a separate control flow controls and steers the work. A diagram of the general overview of a multi-threaded Geant4 application is shown here:
The user interacts with the master that is responsible of creating and controlling worker threads. Before the simulation is started per-event seeds are generated by the mastaer. This operation guarantees reproducibility. Once thread are spawned and configured, each worker is responsible of creating a new G4Run and for simulating a sub-set of the events. At the end of the run the results from each run are merged into the global run. Details on how to interact with a multi-threaded simulation are discussed in the Guide for Application Developers".
Geant4 parallelization makes use of POSIX standard. The use of thid standards in Geant4 guarantees maximum portability between system and integration with advanced parallelization frameworks (for example we have verified this model co-works with TBB and MPI).
To effectively reduce the memory consumption in a multi-threaded application, workers share instances of objects that consume the majority of memory (geometry and physics tables); workers own thread-private instances of the other classes (e.g. SensiticeDetectors, hits, etc). This choice allowed the design of a lock-free code (i.e. no use of mutex during the event loop), this guarantees maximum scalability (cfr: Euro-Par2010, Part II LNCS6272, pp.287-303). Thread safety is obtained via Thread Local Storage.
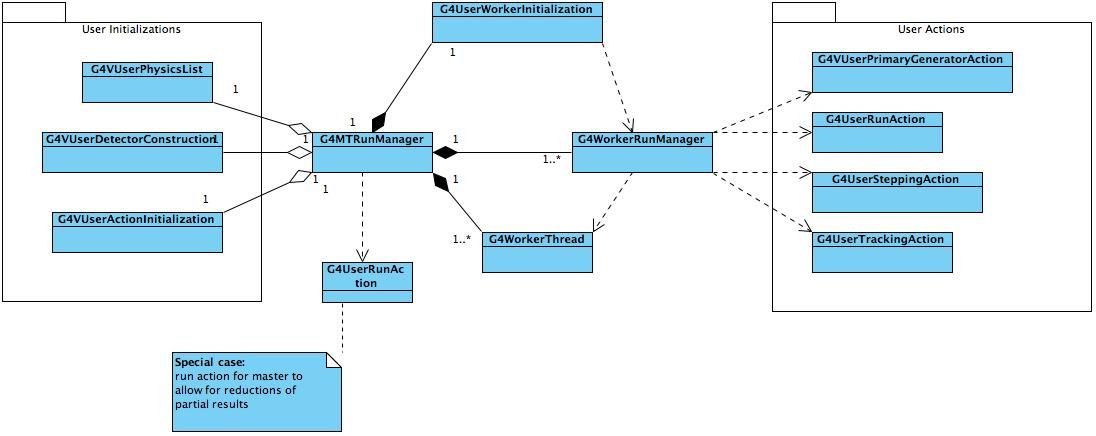
In a similar way to the sequential version of Geant4, master and workers are represented by instances of classes inheriting from G4RunManager: the G4MTRunManager class represents the master model, while G4WorkerRunManager instances represent worker models. The user is responsible of instantiating a single G4MTRunManager (or derived user-class) instance. This class will instantiatiate and control one or more G4WorkerRunManager instances. User should never instantiate directly an instance of G4WorkerRunMAnager class.
A simplified class-diagram of the relevant classes for multi-threading and their relationship is shown here:
As in sequential Geant4 user interacts with Geant4 kernel via user-initializations and user-actions. User initializations (G4VUserDetectorConstruction, GVUserPhysicsList and the new G4VUserActionInitializtion) instances are shared among all threads (as such they are registered to the G4MTRunManager instance); while user actions (G4VUserPrimaryGeneratorAction, G4UserRunAction, G4UserSteppingAction and G4UserTrackingAction) are not shared and a separate instance exists for each thread. Since the master does not perform simulation of events user actions do not have functions for G4MTRunManager and should not be assigned to it. G4RunAction is the exception to this rule since it can be attached to the master G4MTRunManager to allow for merging of partial results produced by workers.
In Geant4 we distinguish two broad types of classes: ones whose instances are separate for each thread (such as a physics process, which has a state), and ones whose instances are shared between threads (e.g. an element G4Element which holds constant data ).
In a few cases classes exist which have a mixed beahvior - part of their state is constant, and part is per-worker. A simple example of this is a particle definitions, such as G4Electron, which holds both data (which is constant) and a pointer to the G4ProcessManager object for electrons - which must be different for each worker (thread).
We handle these 'split' classes specially, to enable data members and methods which correspond to the per-thread state to give a different result on each worker thread. The implementation of this requires an array for each worker (thread) and an additional indirection - which imposes a cost for each time the method is called. However this overhead is small and has been measured to be about 1%. In this section we will discuss the details of how we achieve thread-safety for different use-cases. The information contained here is of particular relevance for toolkit developers that need to adapt code to multi-threading to increase performances (tipically to reduce the memory footprint of an application sharing between threads memory consuming objects). It is however of general interest to understand some of the more delicate aspects of multi-threading.
To better understand how memory is handled and what are the issues introduced by multi-threading it is easier to proceed with a simplified example.
Let us consider the simplest possible class G4Class that consists of a single data member:
class G4Class {
[static] G4double fValue; //static keyword is optional
};
Our goal is to transform the code of G4Class to make it thread-safe. A class (or better, a method of a class) is thread-safe if more than one thread can simultaneously operate on the class data member or its methods without interfering with each other in an unpredictable way. For example if two threads concurrently write and read the value of the data field fValue and this data field is shared among threads, the two threads can interfere with each other if no special code to synchronize the thread is added. This condition is called data-race and is particular dangerous and difficult to debug.
A classical way to solve the data-race provelm is to protect the critical section of the code and the concurrent access to a shared memory location using a lock or a mutex (see section Threading model utilities and functions. However this technique can reduce overall performances because only one thread at a time is allowed to be executed. It is important to reduce at the minimum the use of locks and mutexes, especially in the event loop. In Geant4 we have achieved thread-safety via the use of thread local storager. This allow for a virtually lock-free code at the price of an increased memory footprint and a small CPU penalty. For an explanation of what is thread local storage several external resources exists, for a very simple introduction, but adequate for our discussion, web resources give enough details (e.g. wikipedia).
Before going into the details of how to use thread-local-storage mechanism we need to introduce some terminology.
We define an instance of a variable thread-local(or thread-private) if each thread owns a copy of the variable. A thread-shared variable, on the contrary, is an instance of a variable that is shared among the threads (i.e. all thread have access to the same memory location holding the value of the variable). If we need to share the same memory location containing the value of fValue between several instances of G4Class we call the data field instance-shared otherwise (the majority of the cases) it is instance-local. These defintion are an over-simplification that does not take into account pointers and sharing/ownership of the pointee, however the issues that we will discuss in the following can be extended to the case of pointers and the (shared) pointee.
It is clear that, for the case of thread-shared variables, all thread needs synchronization to avoid data-race conditions (it is worth to remind that there are no race conditions if the variable is accessed only to be read, for example in the case the variable is marked as const.
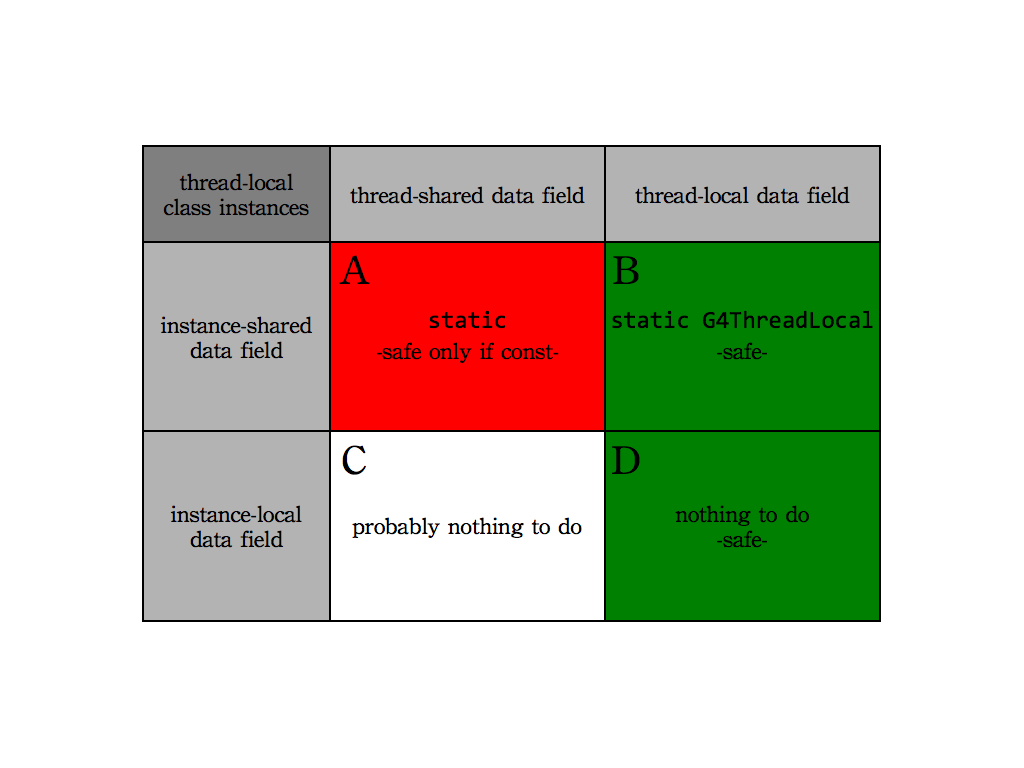
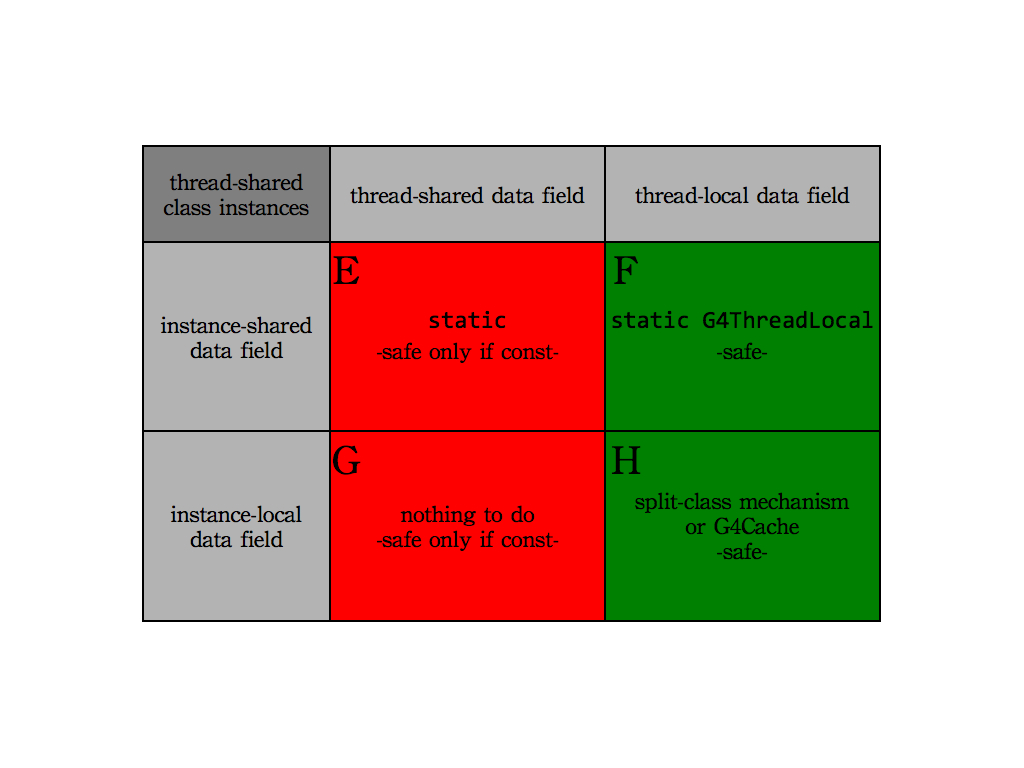
One or more instances of G4Class can exist at the same time in our application. These instances can be thread-local (e.g. G4VProcess) or thread-shared (e.g. G4LogicalVolume). In addition the class data field fValue can be by itself thread-local or thread-shared. The actions to be taken to transform the code depend on three key aspects:
This gives rise to 8 different possible combinations, summarized in the following figures, each one discussed in detail in the following.
In this case each thread has its own instance(s) of type G4Class. We need to share fValue both among threads and among instances. As for a sequential application, we can simply add the static keyword to the declaration of fValue. This technique is common in Geant4 but has the disadvantage that the result code is thread-unsafe (unless locks are used). Trying to add const or modify its value (with the use of a lock ) only outside of the event loop is the simplest and best solution:
class G4Class {
static const G4double fValue;
};
This scenario is also common in Geant4: we need to share a variable (e.g. a data table) between instances of the same class. However it is impractical or it would lead to wrong results if we share among threads fValue (i.e. the penalty due to the need of locks is high or the data field holds a event-dependent information). To make the code thread-safe we mark the data field thread-local via the keyword G4ThreadLocal:
#include "G4Types.hh"
class G4Class {
static G4ThreadLocal G4double fValue;
};
It should be noted that only simple data types can be declared G4ThreadLocal. More information and the procedures to make an object instance thread-safe via thread-local-storage are explained in this web-page.
A possible use-case is the need to reduce the application memory footprint, providing a component to the thread-local instances of G4Class that is shared among threads (e.g. a large cross-section data table that is different for each instance). Since this scenario strongly depends on the implementation details it is not possible to define a common strategy that guarantees thread-safety. The best one being to try to make this shared component const.
This case is the simplest, nothing has to be changed in the original code.
For what thread-safety is concerned this case is equivalent to Case A, and the same recommendations and comments hold.
For what thread-safety is concerned this case is equivalent to Case B, and the same recommendations and comments hold.
Since the class instances are shared among threads the data field are automatically thread-shared. No action is needed, however access to data field is, in general thread unsafe, and the same comments and recommendations done for Case A are valid.
This is the most complex case and it is relatively common in Geant4 Version 10.0. For example G4ParticleDefinition instances are shared among the threads, but the G4ProcessManager pointer data field needs to be thread and instance local. To obtain thread-safe code two possible solutions exists:
G4Cache).
We will here describe the split-class mechanism, central in Geant4 multi-threading, developing a thread-safe split-class starting from our simplified example of G4Class. It will be clear that this techniques allows for minimal changes of public API of the classes and thus is very suitable to make thread-safe code without breaking back-compatibility.
To better describe the changes we introduce a setter and a getter in the sequential version of our class (e.g. before migration to multi-threading):
class G4Class
{
private:
G4double fValue;
public:
G4Class() { }
void SetMyData( G4double aValue ) { fValue = aValue; }
G4double GetMyData() const { return fValue; }
};
Instances of this class will be shared among threads (because it is a memory consuming objects) and we want to transform this class to a split-class.
As a first step we add to the declaration of fValue the TLS keyword G4ThreadLocal (in a POSIX system, is a typedef to __thread). Unfortunately there are several constraints on what can be specified as TLS. In particular the data member has to be declared static (or being a global variable):
#include "tls.hh"
class G4Class
{
private:
static G4ThreadLocal G4double fValue;
public:
G4Class() { }
void SetMyData( G4double aValue ) { fValue = aValue; }
G4double GetMyData() const { return fValue; }
};
G4ThreadLocal G4double G4Class::fValue = -1;
The problem occurs if we need more than one instance of type G4Class with a instance-local different value of fValue. How to obtain this behavior now that the we have declared the data member as static? The method used to solve this problem is called split class mechanism. The idea is to collect all thread-local data fields into a new separate class, instances of which (one per original instance of G4Class) are organized in an array. This array is accessed via a index representing a unique identifier of a given class instance.
We can modify the code as follow:
class G4ClassData {
public:
G4double fValue;
void intialize() {
fValue = -1;
}
};
typedef G4Splitter>G4ClassData< G4ClassManager;
typedef G4ClassManager G4ClassSubInstanceManager;
#define G4MT_fValue ((subInstanceManager.offset[gClassInstanceId]).fValue)
class G4Class {
private:
G4int gClassInstanceId;
static G4ClassSubInstanceManager subInstanceManager;
public:
G4Class()
{
gClassInstanceId = subInstanceManager.CreateSubInstance();
}
void SetMyData( G4double aValue ) { G4MT_fValue = aValue; }
G4double GetMyData() const { return G4MT_fValue; }
};
G4ClassSubInstanceManager G4Class::subInstanceManager;
template >class G4ClassData< G4ThreadLocal G4int G4Splitter>G4ClassData<::workertotalspace = 0;
template >class G4ClassData< G4ThreadLocal G4int G4Splitter>G4ClassData<::offset = 0;
As one can see the use of the value of fValue variable is very similar to how we use it in the original sequential mode, all the handling of the TLS is done in the template class G4Splitter that can be implemented as:
template <class T>
class G4Splitter
{
private:
G4int totalobj;
public:
static G4ThreadLocal G4int workertotalspace;
static G4ThreadLocal T* offset;
public:
G4Splitter() : totalobj(0) {}
G4int CreateSubInstance()
{
totalobj++;
if ( totalobj > workertotalspace ) { NewSubInstances(); }
return (totalobj-1);
}
void NewSubInstances()
{
if ( workertotalspace >=totalobj ) { return; }
G4int originaltotalspace = workertotalspace;
workertotalspace = totalobj + 512;
offset = (T*) realloc( offset , workertotalspace * sizeof(T) );
if ( offset == 0 )
{
G4Excepetion( "G4Splitter::NewSubInstances","OutOfMemory",FatalException,"Cannot malloc space!");
}
for ( G4int i = originaltotalspace; i< workertotalspace ; i++)
{
offset[i].intialize();
}
}
void FreeWorker()
{
if ( offset == 0 ) { return; }
delete offset;
}
};
Let's consider a function that can be called concurrently by more than one thread:
#include "G4Class.hh"
//Variables at global scope
G4Class a;
G4Class b;
void foo()
{
a.SetMyData(0.1); //First instance
b.SetMyData(0.2); //Second instance
G4cout << a.GetMyData()<< " "<< b.GetMyData() << G4endl;
}
We expect that each thread will write on screen: "0.1 0.2"
When we declare the variable a, the static object subInstanceManager in memory has the state:
totalobj = 0 TLS workertotalspace = 0 TLS offset = NULL
The constructor of G4Class calls CreateSubInstance, and since at this point totalobj equals 1, G4Splitter::NewSubInstances() is called. This will create a buffer of 512 pointers of type G4ClassData, each of them is initialized (via G4ClassData::initialize()) to the value -1. Finally, G4Splitter::CreateSubInstance() returns 0 and a.gClassInstanceId equals 0. When a.SetMyData(0.1) is called, the call is equivalent to:
subInstanceManager.offset[0].fValue = 0.1;
When now we declare the instance b the procedure is repeated, except that, since totalobj now equals 1 and workertotalspace is 512, there is no need to call G4Splitter::NewSubInstances() and we use the next available array position in offset. Only if we create more than 512 instances of G4Class memory array is reallocated with more space for the new G4ClassData instances.
Since offset and workertotalspace are marked G4ThreadLocal this mechanism allows each thread to have its own copy of fValue The function foo() can be called from different threads and they will use the thread-shared a and b to access a thread-local fValue data field. No data-race condition occurs and there is no need of mutexes and locks.
An additional complication is that if the initialization of the thread-local part is not trivial and we want to copy some values from the corresponding values of the master thread (in our example, how to initialize fValue to a value that depends on the run condition?). The initial status of the thread-local data field must be initialized, for each worker, in a controlled way. The run cateogory classes must be modified to preapre the TLS space of each thread before any work is being performed.
The following diagram shows the chain of calls in G4ParticleDefinition when a thread needs to access a process pointer:
In Geant4 Version 10.0 the following are split-classes:
In the following some utility classes and functions to help memory handling are discussed. Before going in the detail it should be noted that all of these utilities have a (small) CPU and memory performance penalty, they should be used with caution and only if other simpler methods are not possible. In some cases limitations are present.
In many cases this is not needed the full functionality of split-classes and what we really want are independent thread-local and instance-local data field in thread-shared instances of G4Class. A concrete example being a class representing a cross-section that is made shared because of its memory footprint. It requires a data field to act as a cache to store a value of a CPU intensive calculation. Since different thread share this instance we need to transform the code in a manner similar to what we do for split-classes mechanism. The helper class G4Cache can be used for this purpose (note that the complication of the initial value of the thread-local data field is not present in this case).
G4Cache is a template class that implements a light-weight split-classes mechanism. Being a template it allows for storing any user-defined type. The public API of this class is very simple and it provides two methods
T& G4Cache>T<::Get() const; void G4Cache>T<::Put(const T& val) const;
to access a thread-local instance of the cached object. For example:
#include "G4Cache.hh"
class G4Class {
G4Cache>G4double< fValue;
void foo() {
// Store a thread-local value
G4double val = someHeavyCalc();
fValue.Put( val );
}
void bar() {
//Get a thread-local value:
G4double local = fValue.Get();
}
};
Since Get returns a reference to the cached object is possible to avoid to use Put to update the cache:
void G4Class::bar() {
//Get a reference to the thread-local value:
G4double &local = fValue.Get();
// Use local as in the original sequential code, cache is updated, without the need to use Put
local++;
}
In case the cache holds an instance of an object it is possible to implement lazy initialization, as in the following example:
#include "G4Cache.hh"
class G4Class {
G4Cache>G4Something*< fValue;
void bar() {
//Get a thread-local value:
G4Something* local = fValue.Get();
if ( local == 0 ) {
local = new G4Something( …. );
//warning this may cause a memory leak. Use of G4AutoDelete can help, see later
}
}
};
Since the use of G4Cache implies some CPU penalty, it is a good practice to try to minimize its use.For example, do not use single G4Cache for several data fields, instead use a helper structure as the template parameter for G4Cache:
class G4Class {
struct {
G4double fValue1;
G4Something* fValue2;
} ToBeCached_t;
G4Cache < ToBeCached_t > fCache;
};
Two specialized versions of G4Cache exist that implement the semantics of std::vector and std::map
A detailed example of the use of these cache classes is discussed in the unit test source/global/management/test/testG4Cache.cc.
During the discussion about G4Cache we have shown the example of storing a pointer to a dynamically created object. A common problem is to correctly delete this object at the end of its lifecicle. Since the G4Class instance is thread-shared, it is not possible to delete the cached object in the destructor of G4Class because it is called by the master and the thread-local instances of the cached object will not be deleted. In some cases, to solve this problem, it is possible to use a helper introduced in the namespace G4AutoDelete. A simplified garbage collection mechanism without reference counting is implemented:
#include "G4AutoDelete.hh"
void G4Class::bar() {
//Get a thread-local value:
G4Something* local = fValue.Get();
if ( local == 0 ) {
local = new G4Something( …. );
G4AutoDelete::Register( local ); //All thread instances will be delete automatically
}
}
This technique will delete all instances of the registered objects at the end of the program, after the main function has returned (if they would have been declared static).
This method has several limitations:
In addition, since the objects will be deleted after the main program exit in a non-specified order, it is recommented to provide a very simple destructor that does not depend on other objects (in particular should not call any kernel functionality).
In Geant4 the singleton pattern is used in several cases. The majority of the managers are implemented via the singleton pattern, that in the most simple implementation is:
class G4Singleton {
public:
G4Singleton* GetInstance() {
static G4Singleton anInstance;
return&anInstance;
}
};
With multi-threading many managers and singletons are thread-local. For this reason they have been transformed to:
class G4Singleton {
private:
static G4ThreadLocal* instance;
public:
G4Singleton* GetInstance() {
if ( instance == 0 ) instance = new G4Singleton;
return instance;
}
};
This causes a memory leak: it is not possible to delete thread-local instances of the singletons. To solve this problem the class G4ThreadLocalSingleton has been added to the toolkit. This template class has a single public method T* G4ThreadLocalSingleton<T>::Instance() that returns a pointer to a thread-local instance of T. The thread-local instances of T will be deleted, similartly to the case of G4Cache, at the end of the program.
The example code can be transformed to:
#include "G4ThreadLocalSingleton.hh"
class G4Singleton {
friend class G4ThreadLocalSingleton>G4Singleton<;
public:
G4Singleton* GetInstance() {
static G4ThreadLocalSingleton>G4Singleton< theInstance;
return theInstance.Instance();
}
};
Geant4 parallelism is based on POSIX standards and in particular on the pthreadslibrary. However all functionalities have been wrappedaround Geant4 specific names. This will allow to include WIN32 threading model. In the following a list of the main functionalities available in global/management category are discussed.
G4Thread defines the type for threads (POSIX pthread_t). The types G4ThreadFunReturnType and G4ThreadFunArgType define respectively the return value and the argument type for a function executed in a thread. Use G4THREADCREATE and G4THREADJOIN macros to respecively create and join a thread. G4Pid_t is the type for the PID of a thread.
Example:
#include "G4Threading.hh"
//Define a thread-function using G4 types
G4ThreadFunReturnType myfunc( G4ThreadFunArgType val) {
double value = *(double*)val;
MESSAGE("value is:"<<value);
return /*(G4ThreadFunReturnType)*/NULL;
}
//Example: spawn 10 threads that execute myfunc
int main(int,char**) {
MESSAGE( "Starting program ");
int nthreads = 10;
G4Thread* tid = new G4Thread[nthreads];
double *valss = new double[nthreads];
for ( int idx = 0 ; idx < nthreads ; ++idx ) {
valss[idx] = (double)idx;
G4THREADCREATE(&(tid[idx]) , myfunc,&(valss[idx]) );
}
for ( int idx = 0 ; idx < nthreads ; ++idx ) {
G4THREADJOIN( (tid[idx]) );
}
MESSAGE( "Program ended ");
return 0;
}
G4Mutex is the type for mutexes in Geant4 (POSIX pthread_mutex_t). The G4MUTEX_INITIALIZER and G4MUTEXINIT macros are used to initialize a mutex. Use G4MUTEXLOCK and G4MUTEXUNLOCK functions to lock/unlock a mutex. G4AutoLock class helps the locking/unlocking of a mutex and should be always be used instead of G4MUTEXLOCK/UNLOCK.
Example:
#include "G4Threading.hh"
#include "G4AutoLock.hh"
//Create a global mutex
G4Mutex mutex = G4MUTEX_INITIALIZER;
//Alternatively, call in the main function G4MUTEXINIT(mutex);
//A shared resource (i.e. manipulated by all threads)
G4int aValue = 1;
G4ThreadFunReturnType myfunc( G4ThreadFunArgType ) {
//Explicit lock/unlock
G4MUTEXLOCK(&mutex );
++aValue;
G4MUTEXUNLOCK(&mutex );
//The following should be used instead of the previous because it guarantees automatic
//unlock of mutex.
//When variable l goes out of scope, G4MUTEXUNLOCK is automatically called
G4AtuoLock l(&mutex);
--aValue;
//Explicit lock/unlock. Note that lock/unlock is only tried if mutex is already locked/unlock
l.lock();
l.lock();//No problem here
++aValue;
l.unlock();
l.lock();
--aValue;
return /*(G4ThreadFunReturnType)*/NULL;
}
A complete example of the usage of these functionalities is discussed in the unit test source/global/management/test/ThreadingTest.cc.
Conditions are also available via the G4Condition type, the G4CONDITION_INITIALIZER macro and the two functions G4CONDITIONWAIT and G4CONDITIONBORADCAST. The use of condition allows to implement the barrier mechanism (e.g. synchronization point for threads). A detailed example on the use of condition and how to implement correctly a barrier is discussed in G4MTRunManager code (at the end of file source/run/src/G4MTRunManager.cc). In general there should be no need for kernel classes (with the exception of run category) to use conditions since threads are considered independent and do not need to communicate between them.
In this chapter we have discussed in detail what are probably the most critical aspects of multi-threading capabilities in Geant4. Additional material can be found in online resources. The main entry point is the Geant4 multi-threading task-force twiki page. The Application Developers Guide contains general information regarding multi-threading that is also relevant for Toolkit Developers.
A beginner guide to multi-threading targeted to Geant4 developers has been presented during the 18th Collaboration Meetingr: agenda
For additional information consult this page and this page
Several contributions at the 18th Collaboration Meeting discuss multi-threading:
Finally few articles and proceedings have been prepared:
| December 2013 - First version. Adapted from Multi-threading task-force twiki web-pages |
| |  | |
| 2.13. Intercoms |  | Chapter 3. Extending Toolkit Functionality |